人口数哑变量_人口普查(3)
日期:2021-03-19 类别:热点图片 浏览:
png,233x347,28362b
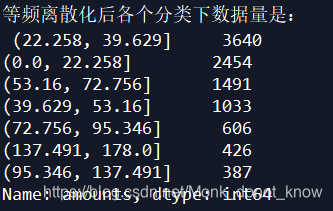
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
png,425x827,62653b
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
png,207x319,29119b
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
png,336x654,75660b
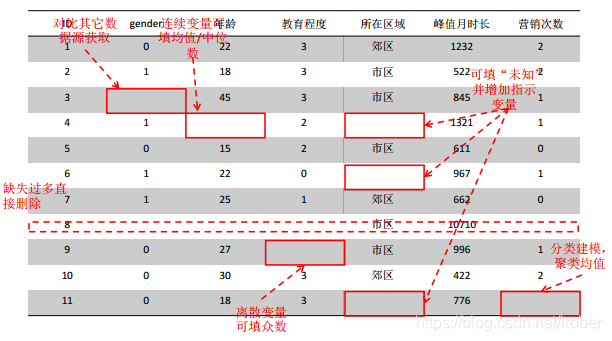
这里面年龄为连续变量,居住地为两分类变量、受教育程度为有序分类变量,从数据情况来看,自变量类型比较杂,年龄和居住地可以直接纳入模型分析,受教育程度可以设置哑变量形式引入模型,但是这样一来,相当于把该变量分散开,无法作为一个完整的变量进行分析了,在此,我们使

,"height":203x470,3271b
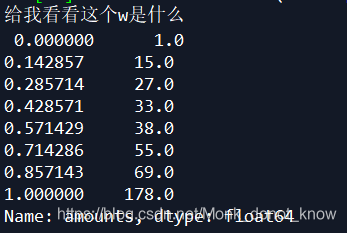
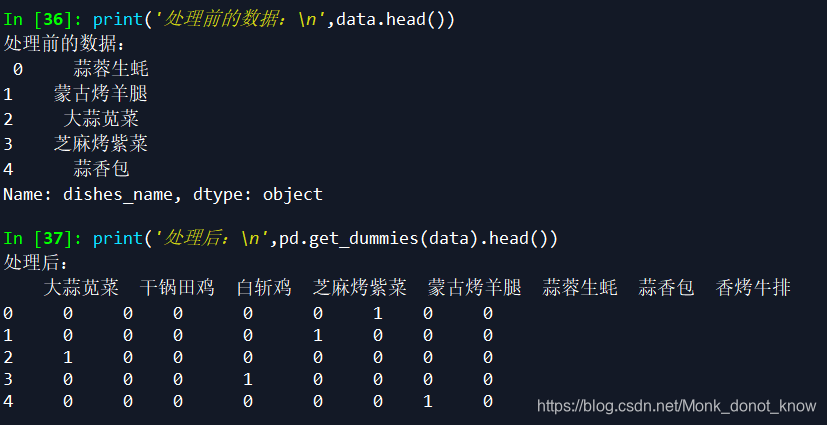
现在希望将上面的表格前两列转化为哑变量,并加入第三列weight数值:_ 可选prefix参数添加前缀,prefix_sep添加分隔符,示例如下:_ 1. dummy variable(哑变量)_ 这里主要介绍get_dummies函数,其功能主要是
png,244x241,17255b
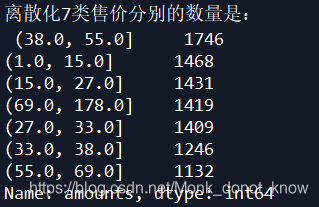
压缩之后的分类变量还是会生成若干个哑变量.
png,309x208,27181b
压缩之后的分类变量还是会生成若干个哑变量.

png,211x333,32244b
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
jpg,250x530,27693b
当数据中的自变量有多分类变量(本例中自变量均为二分类变量或连续性变量)时,需要 对变量赋哑变量较为简便的做法是在\"model\"语句之前加\"class xl(param = ref ref='1'):\" \"x1\"即为多分类变量.\"ref ='1'意为变量的各

png,440x604,20868b
这里我们常以最常用的3倍标准差法为例,将超过3倍标准差的数据调整为3倍标准差_ 数据转化(数据标准化及设置哑变量)_ 1、数据标准化_ (1)min-max标准化:_ (2)z-score标准化_ #min-max标准化_ 8、收益与风险类因子

png,341x612,59524b
1.3噪声值处理_ 1、单变量离群值发现_ 极端值_ · 设置标准,如: 5倍标准差之外的数据_ · 极值有时意味着错误,应重新理解数据,例如:特殊用户的超大额消费_ 离群值_ · 另外每个有缺失值的变量生成一个指示哑变量,参与后续_ 的建模
,"height":325x640,39109b
会识别手语并说话的手套,将改变数千万聋哑人命运
推荐阅读



相关文章
- 总排名
- 每月排行
- 推荐阅读
- 阅读排行