人口数哑变量_人口普查(2)
日期:2021-03-19 类别:热点图片 浏览:
jpeg,307x550,10348b
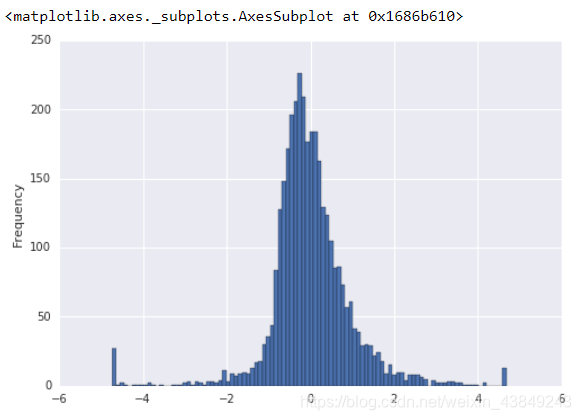
为此我们对除行业哑变量之外的解释变量做了标准化,回归系数的绝对值越大的指标表明,当解释变量变化一个标准差,

jpg,364x601,46686b
如果,两个都设置哑变量的变量开展交互作用分析,那么产生的自变量数排列组合一下,可能3*2

png,420x581,28695b
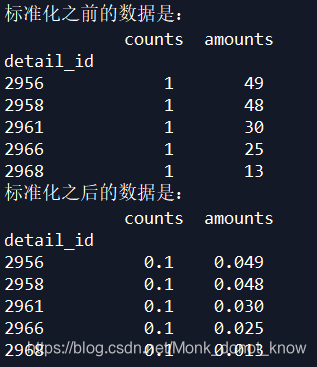
2、哑变量:转化为0或1变量_ 数据转化(数据标准化及设置哑变量)_ 1、数据标准化_ (1)min-max标准化:_ (2)z-score标准化_ #min-max标准化_ #z-score标准化
jpeg,600x1000,144520b
研究人员将不同的营养素按照其摄入水平的5分位进行分组,在构建cox回归模型时,以水平最低的1组为参照组,其余4组设定为4个哑变量进入回归模型.

,"height":186x264,13087b
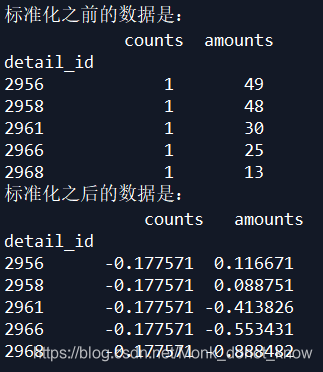
从上图结果可知,_ 除gender变量,其余变量均为数值型变量_ ,那么待会再构建入模变量时,需要对_ gender变量创建哑变量_ ;一般在做数据探索时,需要检查各变量是否存在_ 缺失的情况
,"height":191x303,13167b
从上图结果可知,_ 除gender变量,其余变量均为数值型变量_ ,那么待会再构建入模变量时,需要对_ gender变量创建哑变量_ ;一般在做数据探索时,需要检查各变量是否存在_ 缺失的情况
png,363x518,56635b
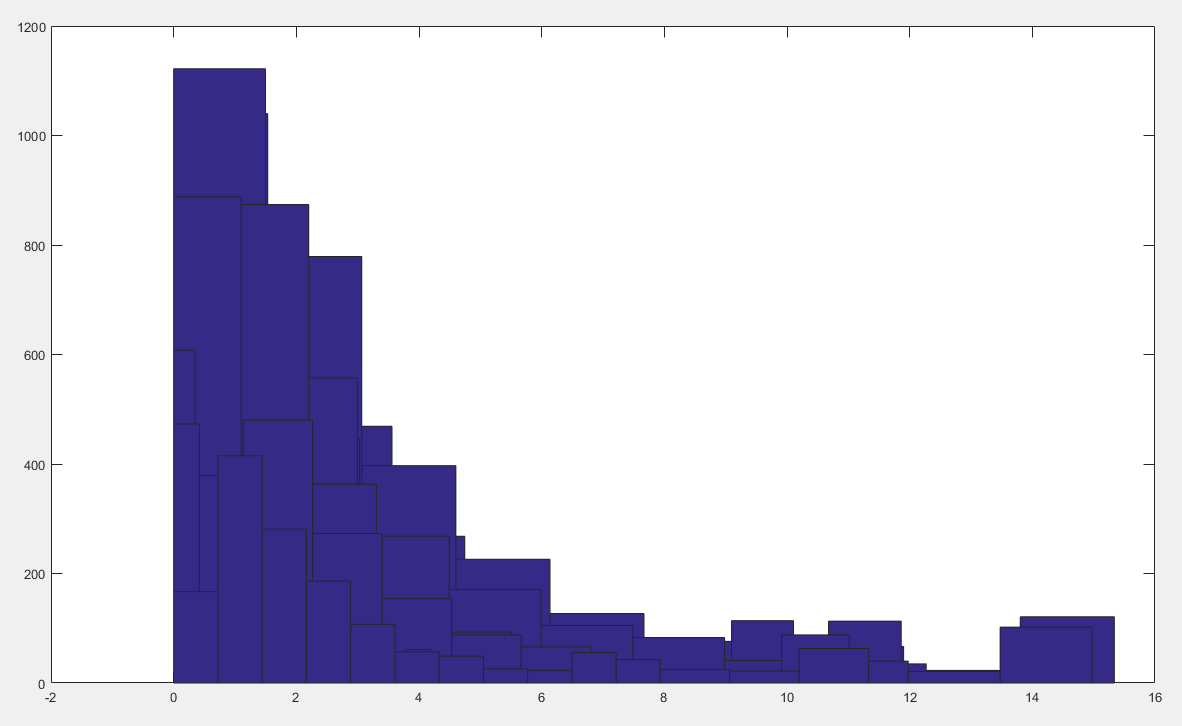
13.2 分类变量的压缩_ 13.2.1 水平变量编码转换_ 1、分类变量重编码(概化)_ a 分类变量的哑变量编码法_ 最后一个水平的哑变量不放入模型中,默认作为对照组.(

png,367x317,34046b
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
png,550x944,57599b
3.3 训练模型_ (1) 数据准备_ 准备训练集、测试集,分别拆分出xtrain,ytrain,xtest,ytest_ 定义k折交叉拆分器 - 用于网格搜索_ 定义回归模型性能查看函数_ (2) lasso回归模型_ 房屋户型 哑变量获取

,"height":330x736,18087b
#拟合广义线性模型_ #同样将验证集划分到四个桶中_ #去掉离群点_ #进行预测_ #计算rmse_ #将数据划到四个区间中_ #将讲年龄编码为哑变量
png,372x323,38994b
4.pandas数据预处理 完 数据清洗 重复值 异常值 缺失值 标准化 哑变量 离散化 无监督分箱
jpg,726x1182,36064b
明显有问题是吧_ 所以如果去掉极值,然后做一下行业中性和市值中性,正态化一下(去极值我一般随意点的,就是把最大最小的0.5%的数据删掉...懒...至于行业中性简单来说就是想剔除行业本身对该因子的影响,可以考虑把中信29个行业作为回归的哑变量,市值的对数
png,355x322,34634b
2、 建模标准流程(适用于工业场景)_ 13.2 分类变量的压缩_ 13.2.1 水平变量编码转换_ 1、分类变量重编码(概化)_ a 分类变量的哑变量编码法_ 最后一个水平的哑变量不放入模型中,默认作为对照组.(

gif,469x471,56760b
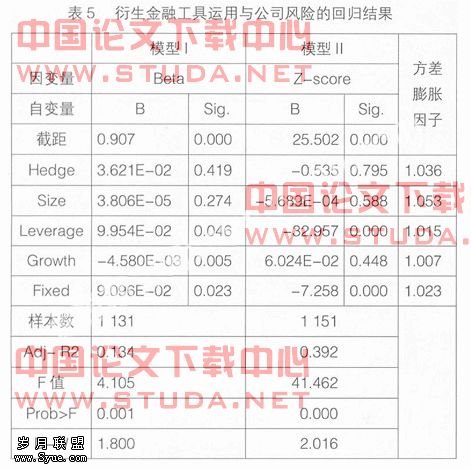
当以系统风险作为公司风险变量时,公司运用衍生金融工具进行风险管理的哑变量估计系数为0.03621,在10%的水平上不显著,可以认为公司运用衍生金融工具进行风险管理增加了公司的beta值,即对公司的系统风险有微弱的增加效应.
推荐阅读



相关文章
- 总排名
- 每月排行
- 推荐阅读
- 阅读排行